Nhận Diện Cảm Xúc Khuôn Mặt Với Python, Keras, Cython và OpenCV.(Part 3) Tiến hành Training model - [Học máy]
Trong phần 3 này. Chúng ta sẽ đi thẳng vào xây dựng mô hình CNN cho model nhận dạng đã được viết ở phần 2.
Một mô hình học sâu thường có 3 nhiệm vụ được kết hợp trong một kiến trúc mạng duy nhất:
- Các lớp đặc trưng (features): có nhiệm vụ chuyển đổi các đặc trưng thành dạng dữ liệu phù hợp để xử lý, chẳng hạn như các tầng tích chập (convolution), mẫu (subsampling), pooling,…
- Các lớp mô hình (modeling): sử dụng các thuật toán học để khái quát hóa dữ liệu, chẳng hạn nơron network, restricted BM, DBN, autoencoder,…
- Các lớp giải mã (decoding): dựa trên dữ liệu khái quát biến đổi thành đầu ra (markov random field hoặc những công cụ tương tự).
Mục lục
1. Mô hình CNN mạng
2. Giải thích mô hình
3. Kết quả
1. Mô hình CNN mạng
2. Giải thích mô hình
Kiến trúc gồm 8 khối chính , trong đó có 7 khối CNN và khối cuối là đầu ra softmax.
Đầu tiên, Khối A, ảnh 48x48 đa cấp xám được chuyển vào khối có 64filter, sử dụng kernel filter cỡ 3x3, hàm kích hoạt ReLU, kết quả tính toán được chuyển qua một lớp batch normalization.
Khối này được thiết kế với ý đồ tạo ra 64 đặc trưng cơ bản cho việc phát hiện cảm xúc khuôn mặt. Khối B được thiết kế tương tự khối A, kể việc sử dụng 64 filter, mục tiêu của khối này giúp tổ hợp các đặc trưng cơ bản thành các đặc trưng phức tạp hơn. Kết quả đầu ra khối B được xử lý độc lập trong 2 khối C và D, khối C là một depthwise separable CNN 128 filter , sau đó được chuẩn hóa bởi một lớp batch normalization và max pooling.
Khối D chỉ là một filter nhằm điều chỉnh trọng số của đặc trưng khi tính gộp kết quả với khối C.
Khối E và F cũng được thiết kế tương tự như vậy.
Cuối cùng, sử dụng khối F có 7 filter (tương ứng với 7 loại cảm xúc), kết quả tính toán của CNN được chuyển vào một global average pooling (chuyển kết quả 2D thành vector), kết quả này được xử lý qua một lớp softmax để trả về xác suất của từng loại cảm xúc.
3. Kết quả
Với kịch bản kiểm thử:
1️⃣ Thử nghiệm trên bộ dataset FER 2013
Đầu vào: Tập dữ liệu đã được traning từ trước
Đầu ra: phần trăm độ chính xác trên toàn bộ tập dữ liệu
Sử dụng CNN
2️⃣ Thử nghiệm trên 1 ảnh bất kỳ trong bộ dataset FER 2013
Đầu vào: là ảnh đã được gán nhã bất kỳ, kích thước 48x48
Đầu ra: Cảm xúc gương mặt(độ %)+giới tính
Sử dụng CNN
3️⃣ Thử nghiệm chạy trên webcam thực tế
Đầu vào: Hình ảnh chuyển động trên Webcam
Đầu ra: Cảm xúc gương mặt(độ %)+giới tính
Sử dụng CNN
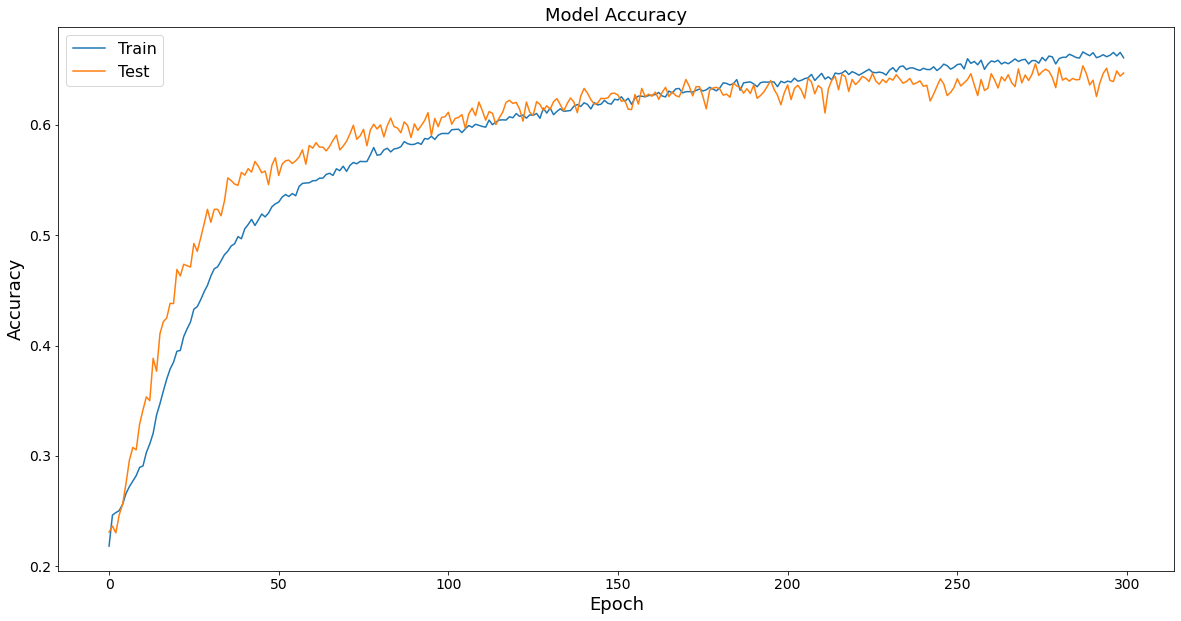
Kết quả thử nghiệm trên dữ liệu kiểm tra đạt mức độ chính xác khoảng 65% (trung bình 300 lần huấn luyện). Trong quá trình huấn luyện độ chính xác thường xuyên cao hơn kết quả kiểm nghiệm trên bộ kiểm tra, nhưng không quá sai khác.
(〜 ̄▽ ̄)〜 Đây là mô hình cơ bản trong CNN.
Để tối ưu chúng ta còn phải áp dụng khi tiền xử lý ảnh, craw dữ liệu, custom loss, cắt tỉa mô hình(Compression model),… 〜( ̄▽ ̄〜)
